

在写并行程序的过程中,经常会需要同步和避免内存竞争,OpenMp是一个高性能计算中常用的多线程库,下面介绍一下其中常见的同步&互斥机制。
1. critical定义临界区
#pragma omp critical用于保护临界区,确保在任何时候只有一个线程可以执行临界区的代码。
这个指令通常用于保护访问共享资源的代码,防止数据竞争和不一致的结果。
int sum = 0;
#pragma omp parallel for
for (int i = 0; i < 10000; i++)
{
#pragma omp critical
{
sum += i;
}
}2. atomic原子操作
原子操作是指在多线程环境中,一个操作或者一系列操作是不可中断的,即这个操作或者这个系列操作要么全部完成,要么全部不完成,不会结束在中间某个环节。原子操作在多线程编程中是必须的,否则当多个线程同时修改某一个数据时,就会出现数据不一致的情况。
int sum = 0;
#pragma omp parallel for
for (int i = 0; i < 10000; i++)
{
#pragma omp atomic
sum += i;
}#pragma omp atomic用于确保某个特定的内存更新操作是原子的,即不可分割的。
在并行编程中,多个线程可能会同时访问和修改同一块内存。如果不进行适当的同步,这可能会导致数据竞争和不一致的结果。#pragma omp atomic指令可以确保某个特定的内存更新操作在任何时候只能被一个线程执行。
例如,以下代码:
#pragma omp atomic
x += 1;这将确保x += 1;这个操作是原子的,即在任何时候只有一个线程可以执行这个操作。这可以防止多个线程同时修改x的值,导致数据竞争和不一致的结果。
注意,
#pragma omp atomic只能用于单个的内存更新操作,不能用于更复杂的代码块。如果你需要同步更复杂的代码块,需要使用上面的#pragma omp critical。
3. barrier同步路障
#pragma omp barrier用于同步所有并行线程。当一个线程到达这个指令时,它会停止执行,直到所有的并行线程都到达这个指令。
这个指令通常用于确保一段并行代码的所有线程在继续执行下一段代码之前都完成了它们的工作。
以下是一个使用#pragma omp barrier的例子:
#include <stdio.h>
#include "omp.h"
int sum = 0;
int main()
{
#pragma omp parallel num_threads(4)
{
for (int i = 0; i < 5; i++)
{
#pragma omp atomic
sum += i;
}
#pragma omp barrier
printf("sum=%d, thread_id=%d\n", sum, omp_get_thread_num());
}
}在这个例子中,所有的线程会先执行for循环,然后在#pragma omp barrier处等待,直到所有的线程都完成了计算再打印结果,运行后可以看到最后所有线程都打印了相同的结果:

可以试着将barrier这一行注释掉看看每个线程打印的结果是否相同,还可以将原子操作atomic注释掉查看还能不能计算出正确结果,或者改成critical看看,写代码就是需要多动手。
注意,
#pragma omp barrier只能在并行区域内使用,不能在并行区域外使用。
4. ordered顺序制导
#pragma omp ordered用于确保在并行循环中的某一部分按照循环的顺序执行,即使循环的其他部分可能是并行的。
在下面的代码中,#pragma omp parallel for ordered指令使得for循环并行执行,但是在#pragma omp ordered指定的代码块中,代码将按照循环的顺序执行。
#include<stdio.h>
#include"omp.h"
int main()
{
#pragma omp parallel for ordered
for (int i = 0; i < 5; i++)
{
printf("[unordered]i=%d, thread_id=%d\n", i, omp_get_thread_num());
#pragma omp ordered
printf("[ordered]i=%d, thread_id=%d\n", i, omp_get_thread_num());
}
}在这个例子中,printf("[unordered]i=%d, thread_id=%d\n", i, omp_get_thread_num());这行代码并行执行,每个线程可以在任何时候执行这行代码。但是printf("[ordered]i=%d, thread_id=%d\n", i, omp_get_thread_num());这行代码按照循环的顺序执行,即使在并行环境中,也会按照i的顺序执行这行代码。
输出结果:
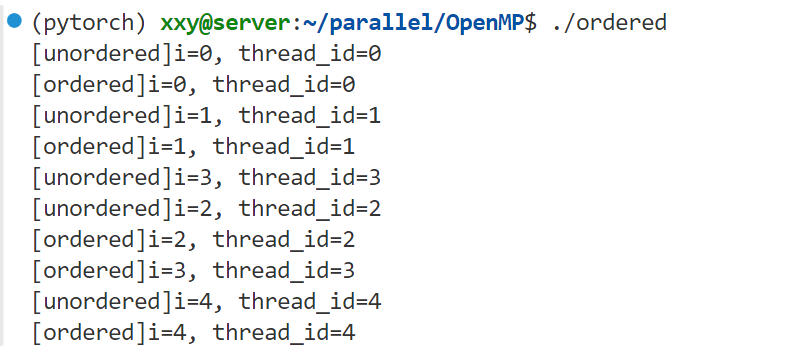
unordered输出的顺序是0-1-3-2-4,而加了ordered的部分输出就是按0~4顺序输出的了。
试着把
#pragma omp parallel for ordered中的ordered去掉看看编译会报什么错。
5. master主线程执行
#pragma omp master用于指定一段只能由主线程(线程ID为0的线程)执行的代码。
在下面的代码中,#pragma omp parallel num_threads(4)指令使得下面的代码块并行执行,但是在#pragma omp master指定的代码块中,代码只能由主线程执行。
#include<stdio.h>
#include"omp.h"
using namespace std;
int main()
{
#pragma omp parallel num_threads(4)
{
printf("thread_id=%d\n", omp_get_thread_num());
#pragma omp master
{
printf("[master]thread_id=%d\n", omp_get_thread_num());
}
}
}因此运行结果如下:

评论区